(주)유알피
유알피가 제공하는 기업/기관 전용 LLM
urLLM logo
- 전용 LLM
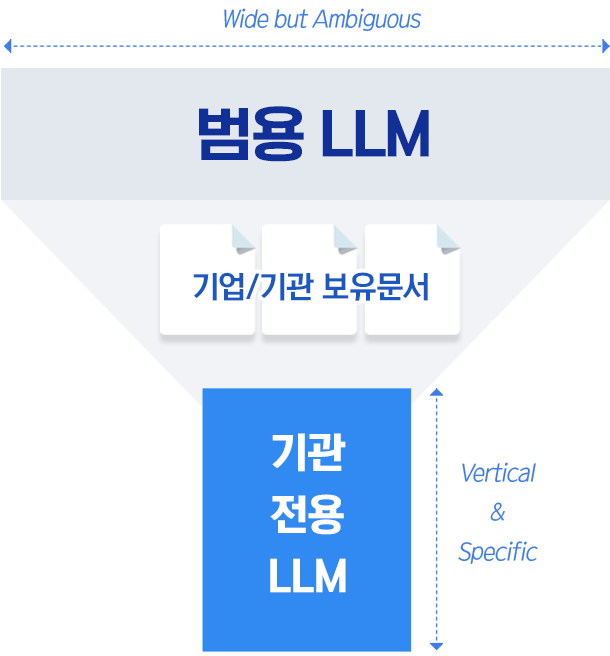
- 범용 LLM의 문제점
- 범용 LLM을 구축하기 위해서는 GPU 1천개가 필요
- 범용 LLM 운영비용 역시 매년 1백억원 이상 소요
- 모든 분야의 지식을 아우르기 위해서는 큰 규모의 LLM이 필요하지만 Hallucination을 피하기는 어려움
- sLLM으로 기관 전용 LLM 구축
- 큰 규모의 LLM을 학습하기 위해서는 수십억 건의 학습데이터가 필요
- 일반적인 기업/기관이 보유한 데이터를 학습하기 위해서는 적절한 규모의 파라미터 수가 필요
- 비용과 데이터량을 고려할 때 기업/기관은 수십억~수백억 규모의 파라미터수의 sLLM이 적합
-
- 특장점
-
-
비용 Down
학습성능 Up- 기업/기관 맞춤형 저비용 sLLM 구성 파인튜닝 비용 최소화 학습 성능 향상
- 파라미터 고효율 미세 조정 파인튜닝 비용 최소화 학습 성능 향상
-
추론속도
추론성능 Up- 병렬추론 알고리즘 적용 추론 속도/성능 향상
- 모델별 배치 처리 추론 효율성 향상
-
답변
신뢰도 Up- 게시글 기반 질의응답 파인튜닝
- NLI (Natural Language Inference)
-
- Tokenizer
-

Domain사전 기반의 Tokenizer
- 형태소분석, NER 등의 자연어처리 알고리즘에는 데이터 처리의 기준이 되는 단어사전이 필요합니다.
- 일반적으로 오픈소스로 공개된 사전을 사용하나,
- 토크나이저 성능 향상을 위해서는 법률/행정/금융/관광/통신 등 도메인별로 사전 구축이 필요합니다.
유알피의 Domain사전
- 법률/행정 Domain사전을 보유하고 있으며, Domain 영역을 확장하여 지속적으로 구축중입니다.
-
-
법률
Domain -
행정
Domain -
금융
Domain -
Commerce
Domain -
통신
Domain -
...
-
- Scalable
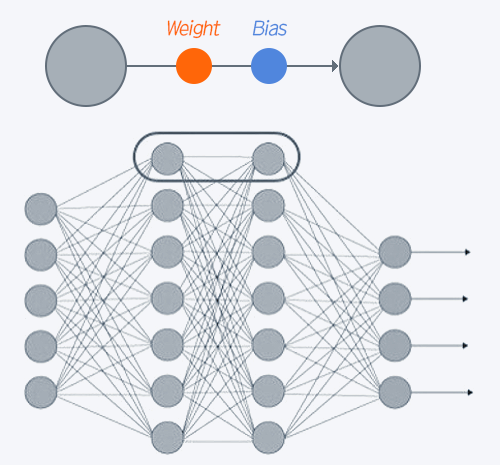
- 파라미터란
- 언어모델을 구성하는 가중치(Weight)와 편향(Bias)을 의미
- 학습 중에 신경망에서 조정되는 값으로, 순전파와 역전파를 반복하면서 값이 조정
- 파라미터 개수는 인간 뇌의 뉴런 수와 비슷하다고 할 수 있으며 파라미터가 많을수록 AI의 성능이 향상
- Scalable LLM이 필요한 이유
- 특정 기관 또는 기업 전용 LLM을 구축하기 위해서는 내부 데이터를 바탕으로 한 추가학습이 필요
- 파라미터 수가 큰 LLM을 학습시키기 위해서는 기관/기업 자체 데이터량도 커야만 의미가 있음
- 따라서, 기관/기업 규모에 따라 적정 규모의 파라미터 수가 필요함
-
- 성능
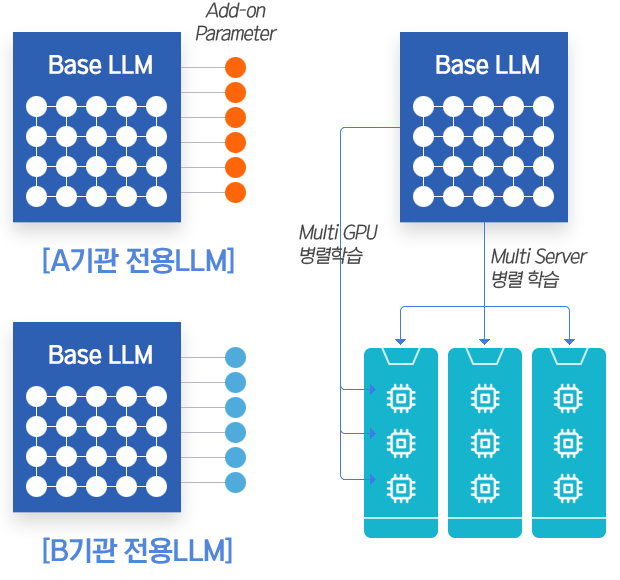
- Add-On 파라미터
- 학습 과정에서 수십~수백억의 파라미터를 갱신하기 위해서는 데이터량도 커야 하고, 많은 GPU리소스가 필요
- 전체를 갱신하지 않고 파라미터를 Add-On 하는 방식으로 학습하면 성능을 크게 개선
- 병렬GPU 학습
- 병렬GPU 또는 다중GPU서버들을 이용하여 분산학습을 함으로써, 학습 시간을 크게 단축
- 학습을 위한 GPU 비용 절감
-